Robots.txt là một tệp văn bản đơn giản nhằm thông báo cho công cụ tìm kiếm không thu thập dữ liệu các trang hoặc phần nhất định của trang web.
Robots.txt giúp kiểm soát việc thu thập dữ liệu của robot công cụ tìm kiếm, nó liệt kê tất cả nội dung bạn không muốn các công cụ tìm kiếm như Google thu thập và lập chỉ mục.
Tệp robots.txt được tìm thấy trong thư mục gốc của tên miền. Đây là tài liệu đầu tiên mà bot truy cập khi truy cập trang web để nhận hướng dẫn thu thập dữ liệu. Tuy nhiên, không có gì đảm bảo rằng bot sẽ tuân thủ hoàn toàn các yêu cầu của robots.txt.
Tệp robots.txt trông như thế nào?
Cách đơn giản để tìm thấy tệp robots.txt của một trang web đó là bạn thêm /robots.txt vào cuối tên miền.
Ví dụ: https://bettergrowth.org/robots.txt
- Bạn sẽ tìm thấy tệp robots.txt.
- Bạn sẽ tìm thấy một tệp tin trống. Điều đó chứng tỏ, trang web của bạn dường như thiếu tệp robots.txt.
- Bạn sẽ nhận được lỗi 404. Điều này có nghĩa là, bạn cần sửa tệp robots.txt của mình.
Nếu bạn tìm thấy robots.txt, màn hình trang web của bạn sẽ trông giống như:
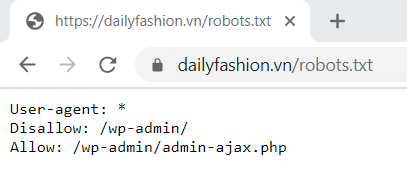
Trong đó:
- User-agent (tiếng Việt: Tác nhân người dùng) là tên của robot công cụ tìm kiếm (phần mềm thu thập dữ liệu web) được áp dụng quy tắc. Đây là dòng đầu tiên của bất kỳ quy tắc nào.
Mỗi công cụ tìm kiếm tự nhận dạng bằng một tác nhân người dùng khác nhau.
Hỗ trợ ký tự đại diện * để gán chỉ thị cho một tiền tố, hậu tố hoặc toàn bộ chuỗi đường dẫn.
Có hàng trăm tác nhân người dùng nhưng dưới đây là một số tác nhân hữu ích cho SEO:
– Google: Googlebot
– Google Hình ảnh: Googlebot-Image
– Cốc Cốc: coccocbot
– Bing: Bingbot
– Yahoo: Slurp
Ví dụ: Bạn chỉ muốn Google thu thập dữ liệu trang web của bạn và chặn tất cả các bot của những công cụ tìm kiếm khác thì bạn sẽ thêm thông tin sau vào tệp robots.txt của mình:
User-agent: *
Disallow: /
User-agent: Googlebot
Allow: /- Disallow (tiếng Việt: Không cho phép) là quy tắc để áp dụng khi bạn muốn tác nhân người dùng không được thu thập dữ liệu thư mục hoặc trang tương ứng với tên miền gốc.
Trong trường hợp bạn muốn loại trừ một trang, bạn phải thêm liên kết đến trang đầy đủ như được hiển thị trong trình duyệt.
Ví dụ: Tôi muốn loại trừ trang “Tiết Lộ & Minh Bạch về Tiếp Thị Liên Kết” có liên kết là “https://bettergrowth.org/affiliate-disclosure/” thì trong tệp robots.txt, tôi sẽ phải thêm thông tin như sau:
Disallow: /affiliate-disclosure/Trong trường hợp bạn muốn loại trừ một thư mục, thư mục phải kết thúc bằng /.
Hỗ trợ ký tự đại diện * để gán chỉ thị cho một tiền tố, hậu tố hoặc toàn bộ chuỗi đường dẫn.
- Allow (tiếng Việt: Cho phép) là quy tắc để áp dụng khi bạn muốn tác nhân người dùng được đề cập được phép thu thập dữ liệu thư mục hoặc trang tương ứng với tên miền gốc.
Quy tắc này dùng để ghi đè Disallow nhằm cho phép thu thập dữ liệu một trang hoặc thư mục con trong một thư mục không được phép.
Tại sao Robots.txt quan trọng?
Hầu hết các trang web không cần tệp robots.txt.
Tuy nhiên để hướng dẫn công cụ tìm kiếm thu thập dữ liệu tốt hơn, bạn nên sử dụng tệp robots.txt.
Có 3 lý do chính mà bạn muốn sử dụng tệp robots.txt:
- Chặn các trang không công khai: Đôi khi bạn có các trang trên trang web của mình mà bạn không muốn lập chỉ mục.
- Tối đa hóa ngân sách thu thập dữ liệu: Bằng cách chặn các trang không quan trọng bằng robots.txt, Googlebot có thể dành nhiều ngân sách thu thập dữ liệu hơn cho các trang thực sự quan trọng.
- Ngăn chặn các tệp hình ảnh, video và tài nguyên xuất hiện trong kết quả tìm kiếm của Google.
Cách tạo tệp robots.txt
Trước khi tạo tệp robots.txt, bạn cần ghi nhớ một vài nguyên tắc:
- Phải đặt tên tệp là robots.txt.
- Website của bạn chỉ có thể có một tệp robots.txt.
- Tệp robots.txt phải nằm ở thư mục gốc của máy chủ website tương ứng.
- Nhận xét là bất kỳ nội dung nào sau dấu #.
- Một tệp robots.txt bao gồm một hoặc nhiều nhóm.
- Mỗi nhóm bao gồm nhiều quy tắc hoặc chỉ thị (hướng dẫn), mỗi chỉ thị tương ứng với một dòng.
- Một nhóm cung cấp các thông tin bao gồm User-agent, Disallow và Allow.
- Các quy tắc phân biệt chữ hoa chữ thường. Ví dụ:
Disallow: /file.pdfáp dụng vớihttp://www.example.com/file.pdfnhưng không áp dụng vớihttp://www.example.com/File.pdf.
Dưới đây là các bước để bạn bắt đầu tạo một tệp robots.txt:
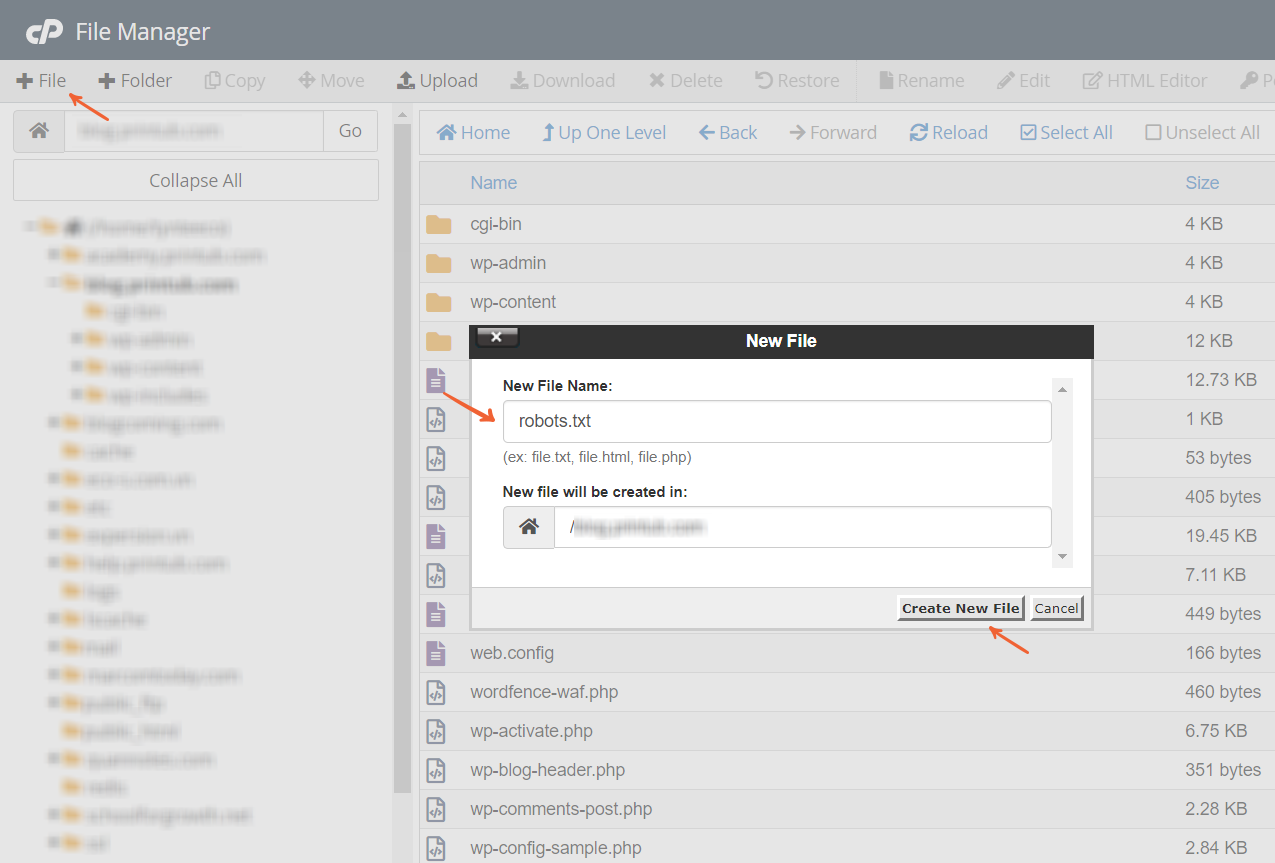
Bước 1: Đăng nhập tài khoản lưu trữ và truy cập phần quản lý thư mục để kiểm tra thư mục gốc của website
Nếu bạn sử dụng cPanel để quản lý thư mục, bạn chỉ cần nhấp vào File Manager:
Sau đó, màn hình hiện ra thư mục gốc website của bạn. Nó trông giống như:
Nếu bạn không có tệp robots.txt, bạn sẽ cần tạo một tệp từ đầu. Ngược lại, nếu bạn đã có một tệp robots.txt, bạn chỉ cần tùy chỉnh lại nó.
Bước 2: Tạo một tệp robots.txt
Có nhiều cách để tạo một tệp robots.txt nhưng nên nhớ, bạn chỉ sử dụng trình soạn thảo văn bản đơn giản cho việc này. Nếu bạn sử dụng các chương trình như Microsoft Word, chúng có thể chèn thêm mã vào văn bản.
Cách 1: Sử dụng phần mềm Notepad trong hệ điều hành Window. Sau khi thêm các quy tắc và chỉ thị, bạn lưu lại và tải tệp robots.txt lên thư mục gốc của website.
Cách 2: Sử dụng trình soạn thảo văn bản trực tuyến trên trang web miễn phí Editpad.org. Sau đó, bạn tải xuống tệp robots.txt rồi tải lên thư mục gốc của website.
Cách 3: Tạo tệp robots.txt ngay trong thư mục gốc của website. Sau đó, bạn chỉnh sửa tệp và lưu lại.
Đối với các trang web WordPress, tôi khuyên bạn nên dùng các quy tắc sau trong tệp robots.txt của mình:
User-agent: *
Allow: /wp-content/uploads/
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /readme.html
Disallow: /tag/
Disallow: /category/
Disallow: /author/
Disallow: /trackback/
Disallow: /feed/
Disallow: /blackhole/
Disallow: /search/
Disallow: /?s=
Disallow: /*&preview=
Sitemap: https://example.com/post-sitemap.xml
Sitemap: https://example.com/page-sitemap.xmlBằng cách thêm “Disallow: /tag/” và “Disallow: /category/” vào tệp robots.txt, bạn có thể giúp website của mình thoát khỏi một số rắc rối với vấn đề nội dung trùng lặp do các trang thẻ và danh mục gây ra.